
itcctv_soft
18/07/2025
Q-Learning

Học tăng cường (Reinforcement Learning - RL) là một phương pháp trong học máy không có giám sát giúp một tác nhân (Agent) học cách thực hiện hành động tối ưu trong một môi trường bằng cách thử nghiệm và nhận phần thưởng. Q-Learning là một thuật toán RL phổ biến. Q-Learning sử dụng Q-Table để lưu trữ giá trị kỳ vọng của mỗi hành động tại từng trạng thái:
![]()
Trong đó:
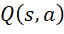 : Giá trị kỳ vọng khi thực hiện hành động
: Giá trị kỳ vọng khi thực hiện hành động 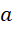 tại trạng thái
tại trạng thái 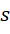 .
.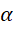 : Hệ số học (learning rate).
: Hệ số học (learning rate).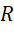 : Phần thưởng nhận được sau hành động.
: Phần thưởng nhận được sau hành động.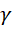 : Hệ số chiết khấu, xác định tầm quan trọng của phần thưởng tương lai.
: Hệ số chiết khấu, xác định tầm quan trọng của phần thưởng tương lai.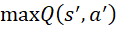 : Giá trị Q tối ưu cho trạng thái tiếp theo
: Giá trị Q tối ưu cho trạng thái tiếp theo
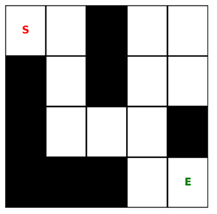
Cho một bài toán sau: Một robot cần tìm đường từ vị trí xuất phát đến đích trong một mê cung. Mê cung có các bức tường (nơi không thể di chuyển) và một đích (nơi cần đến). Robot có thể di chuyển lên, xuống, trái, phải nếu không có chướng ngại vật. Khi đến đích, robot nhận phần thưởng +100.Nếu va vào bức tường, robot nhận phần thưởng -10. Mọi hành động di chuyển bình thường không có phần thưởng (0).
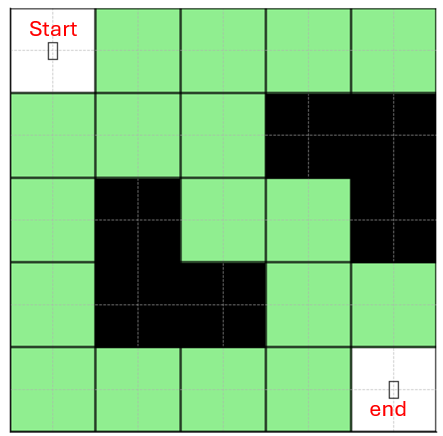
Ảnh 4‑4: Ví dụ mê cung cần phải đi
Triểu khai Q-Learning trong Python
Bước 1: Tạo môi trường mê cung
import numpy as np
import random
import matplotlib.pyplot as plt
# Kích thước mê cung (5x5)
maze_size = (5, 5)
# Bản đồ mê cung (0: có thể đi, -10: tường, 100: đích)
reward_map = np.array([
[0, 0, 0, 0, 100],
[0, -10, -10, 0, 0],
[0, -10, 0, 0, -10],
[0, 0, 0, -10, -10],
[0, 0, 0, 0, 0]
])
# Hành động (0: Trái, 1: Phải, 2: Lên, 3: Xuống)
actions = ["Left", "Right", "Up", "Down"]
# Chọn điểm xuất phát
start_position = (4, 0) # Dưới cùng bên trái
goal_position = (0, 4) # Trên cùng bên phải
Bước 2: Khởi Tạo Q-Table
# Khởi tạo Q-Table với giá trị ban đầu bằng 0
Q_table = np.zeros((*maze_size, len(actions)))
Bước 3: Hàm Di Chuyển
def get_next_position(position, action):
x, y = position
new_x, new_y = x, y
if action == 0 and y > 0: # Trái
new_y -= 1
elif action == 1 and y < maze_size[1] - 1: # Phải
new_y += 1
elif action == 2 and x > 0: # Lên
new_x -= 1
elif action == 3 and x < maze_size[0] - 1: # Xuống
new_x += 1
# Kiểm tra nếu đi vào tường, thì giữ nguyên vị trí
if reward_map[new_x, new_y] == -10:
return position # Không di chuyển nếu gặp tường
return (new_x, new_y)
Bước 4: Huấn Luyện Robot
alpha = 0.1 # Tham số Q-Learning # Learning rate
gamma = 0.9 # Discount factor
epsilon = 1.0 # Khám phá ban đầu
epsilon_decay = 0.99 # Giảm dần epsilon
num_episodes = 500 # Số lần huấn luyện
for episode in range(num_episodes): # Huấn luyện mô hình
position = start_position
done = False
while not done:
# Chọn hành động: Khám phá (epsilon) hoặc khai thác (greedy)
if random.uniform(0, 1) < epsilon:
action = random.randint(0, 3) # Chọn ngẫu nhiên
else:
action = np.argmax(Q_table[position])
# Thực hiện hành động
new_position = get_next_position(position, action)
reward = reward_map[new_position]
# Cập nhật Q-Table
Q_table[position + (action,)] += alpha * (reward + gamma * np.max(Q_table[new_position]) - Q_table[position + (action,)])
# Di chuyển đến vị trí mới
position = new_position
# Kiểm tra nếu đến đích hoặc gặp tường
if position == goal_position or reward == -10:
done = True
epsilon *= epsilon_decay# Giảm epsilon dần để tăng mức độ khai thác
Bước 5: Tìm Đường Đi Tối Ưu
position = start_position
optimal_path = [position]
while position != goal_position:
action = np.argmax(Q_table[position]) # Chọn hành động có giá trị Q lớn nhất
position = get_next_position(position, action)
optimal_path.append(position)
print("Đường đi tối ưu:", optimal_path)
Kết quả đường đi tối ưu là: [(0, 0), (0, 1), (0, 2), (1, 2), (2, 2), (2, 3), (3, 3), (3, 4), (4, 4)]
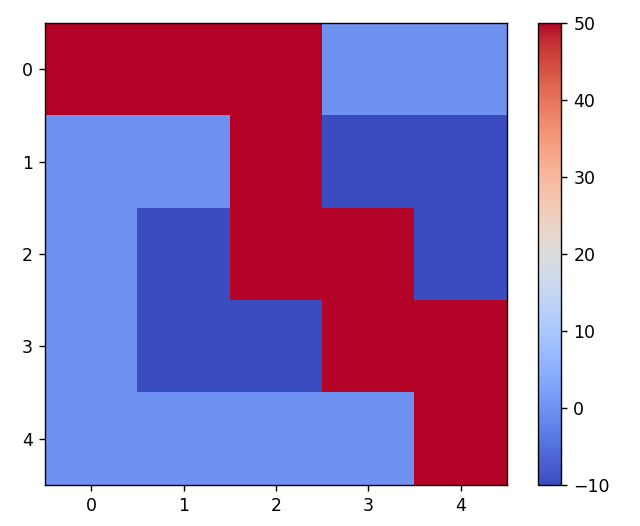
Ảnh 4‑5: Hình ảnh đường đi tối ưu qua mê cung
Q-Learning là một thuật toán mạnh mẽ để học hành động tối ưu. Nó Có thể áp dụng trong nhiều lĩnh vực như robot, tự động hóa, tài chính. Chúng ta có thể mở rộng thành Deep Q-Learning để xử lý các môi trường phức tạp hơn.
















Bình luận