
itcctv_soft
19/07/2025
Phép toán tích chập được sử dụng trong mạng nơ ron tích chập
Phép toán tích chập là quá trình di chuyển một bộ lọc (filter hay kernel) trên toàn bộ hình ảnh đầu vào để tạo ra một bản đồ đặc trưng (feature map). Bộ lọc này trích xuất các đặc trưng như cạnh, góc, hoặc các mô hình cụ thể trong hình ảnh.
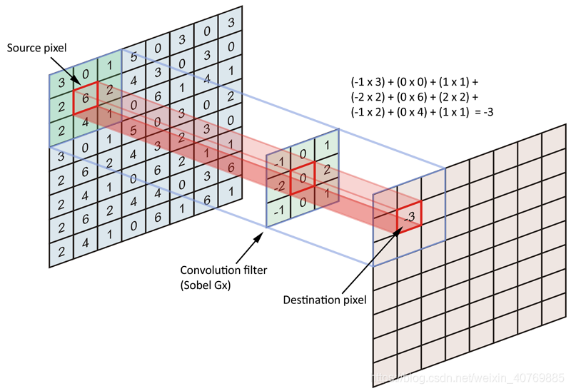
Ảnh 0‑8: Mô tả phép toán tích chập
Hình Ảnh Đầu Vào (Input Image): Là ma trận số (có thể là grayscale hoặc RGB) đại diện cho hình ảnh.
Bộ Lọc (Filter/Kernels): Là một ma trận nhỏ hơn so với hình ảnh đầu vào. Mỗi giá trị trong ma trận này là một trọng số học được trong quá trình huấn luyện.
Tích Chập (Convolution): Bộ lọc di chuyển qua hình ảnh đầu vào, thực hiện phép nhân từng phần tử (element-wise multiplication) giữa các giá trị của bộ lọc và các giá trị tương ứng trong hình ảnh, sau đó cộng tất cả các giá trị lại với nhau để tạo thành một giá trị duy nhất trong bản đồ đặc trưng.
Các thành phần quan trọng trong một phép toán tích chập:
Bộ Lọc (Filter/Kernels)
Kích Thước: Bộ lọc thường có kích thước nhỏ hơn so với hình ảnh đầu vào và là số lẻ, chẳng hạn như 3x3, 5x5, hoặc 7x7. Số lượng bộ lọc xác định số lượng bản đồ đặc trưng được tạo ra từ phép toán tích chập.
Trọng Số (Weights): Mỗi bộ lọc có một tập hợp các trọng số được học trong quá trình huấn luyện. Hay nói cách khác giá trị của bộ lọc chính là trọng số. Mỗi phần tử trong bộ lọc tương ứng với một trọng số, và giá trị của các trọng số này được điều chỉnh thông qua quá trình tối ưu hóa (bằng cách sử dụng các thuật toán như Gradient Descent). Mục tiêu của quá trình này là tìm ra những trọng số tối ưu nhất giúp mô hình nhận diện chính xác các đặc trưng quan trọng từ dữ liệu đầu vào. Trong quá trình huấn luyện CNN, các trọng số trong bộ lọc được cập nhật liên tục dựa trên lỗi giữa dự đoán của mô hình và nhãn thực tế. Các trọng số này đóng vai trò quyết định đặc trưng nào sẽ được bộ lọc đó trích xuất. Ví dụ, một bộ lọc với các trọng số cụ thể có thể học cách nhận diện các cạnh ngang, trong khi bộ lọc khác có thể học cách nhận diện các đường viền.

Ảnh 0‑9: Ví dụ sử dụng phép tích chập để tìm ra các đường viền
Một mạng CNN thường sử dụng nhiều bộ lọc khác nhau trong mỗi lớp tích chập (convolutional layer). Mỗi bộ lọc sẽ có một tập hợp trọng số khác nhau, cho phép mạng trích xuất nhiều loại đặc trưng khác nhau từ cùng một hình ảnh đầu vào. Sau khi bộ lọc di chuyển qua toàn bộ hình ảnh và thực hiện tích chập, nó tạo ra một bản đồ đặc trưng (feature map). Bản đồ này biểu thị các đặc trưng mà bộ lọc đã nhận diện trong hình ảnh. Các giá trị trong bản đồ đặc trưng phụ thuộc trực tiếp vào trọng số trong bộ lọc.
Stride:
Định Nghĩa: Stride là bước di chuyển của bộ lọc trên hình ảnh. Nếu stride là 1, bộ lọc sẽ di chuyển từng pixel một; nếu stride là 2, nó sẽ di chuyển hai pixel một lần.
Stride lớn hơn sẽ làm giảm kích thước của bản đồ đặc trưng, còn stride nhỏ hơn giữ lại nhiều thông tin chi tiết hơn.
Padding:
Định Nghĩa: Padding là kỹ thuật thêm các lớp pixel vào các cạnh của hình ảnh trước khi thực hiện tích chập. Điều này giúp bảo toàn kích thước của bản đồ đặc trưng đầu ra. Có 2 loại: Valid Padding và Same padding. Valid Padding là không thêm bất kỳ pixel nào, điều này làm giảm kích thước của bản đồ đặc trưng. Trong khi đó Same Padding là thêm đủ pixel để bản đồ đặc trưng có cùng kích thước với hình ảnh đầu vào.
Nếu trong phép tích chập padding và stride có giá trị bằng 1 thì kết quả sẽ có kích thước bằng giá trị đầu vào.
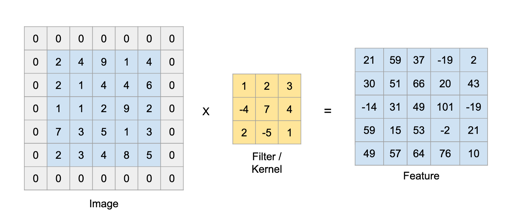
Ảnh 0‑10: Ví dụ về sử dụng phép tích chập với padding = 1 và stride = 1.
Từ phép tích chập truyền thống ban đầu, một bộ lọc di chuyển qua toàn bộ hình ảnh để tạo ra một bản đồ đặc trưng duy nhất cho mỗi bộ lọ, một vài biến thể của phép tích chập đã được phát minh mang lại hiệu quả ở một số khía cạnh.
Dilated Convolution (Tích Chập Giãn Cách): mở rộng phạm vi của bộ lọc bằng cách thêm các khoảng trống giữa các giá trị trong bộ lọc. Điều này giúp tăng kích thước của vùng nhận thức mà không cần tăng số lượng tham số, từ đó tăng tốc độ xử lý của mạng nơ-ron. Được sử dụng nhiều trong các mô hình như DeepLab cho phân đoạn ngữ nghĩa với độ phân giải cao.
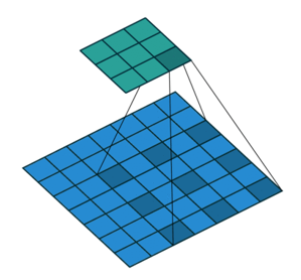
Ảnh 0‑11: Ví dụ minh họa cho Tích chập giãn cách
Transposed Convolution (Tích Chập Ngược): còn được gọi là deconvolution, là một kỹ thuật dùng để tăng kích thước của bản đồ đặc trưng, thường được sử dụng trong phần giải mã (decoder) của các mô hình như U-Net. Thường được dùng trong các mô hình xử lý ảnh như phân đoạn ngữ nghĩa, nơi mà kích thước của ảnh đầu ra cần phải bằng với ảnh đầu vào.
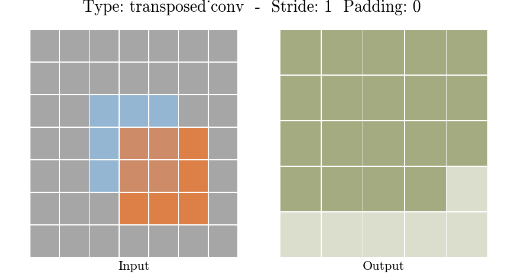
Ảnh 0‑12: Ví dụ minh họa cho phép tích chập ngược. Ma trận màu cam là kernel 3x3, ma trận màu xanh da trời là input, ma trận màu xanh lục là output.
Separable Convolution (Tích Chập Phân Tách): Kỹ thuật này phân chia tích chập thành hai bước: một tích chập theo chiều sâu (depthwise convolution) và một tích chập điểm (pointwise convolution), giúp giảm đáng kể số lượng tham số và chi phí tính toán. Tuy nhiên loại tích chập này được nhận định không hiệu quả trong mọi trường hợp vì nó khócó thể trích xuất các đặc trưng phức tạp.
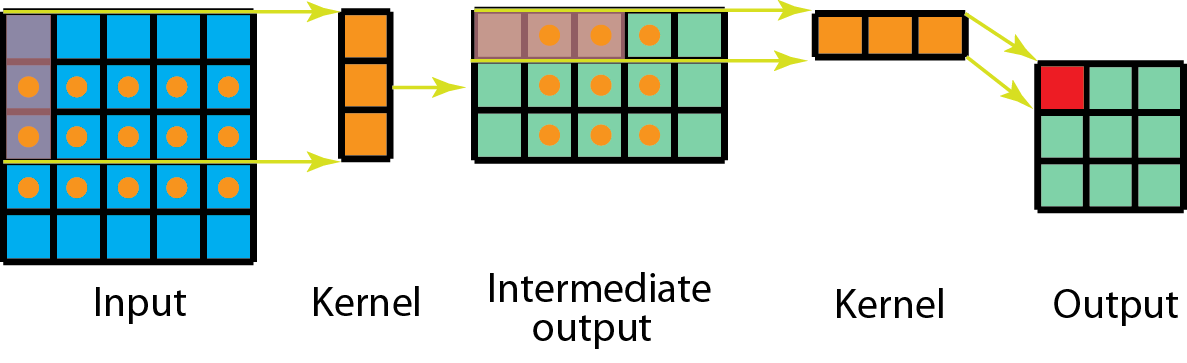
Ảnh 0‑13: Ví dụ về tích chập phân tách
Chúng ta có thể sử dụng thư viên OpenCV để thực hiện phép toán tích chập trên dữ liệu hình ảnh để thấy rõ kết quả của phép toán tích chập. Dựa trên phép toán tích chập, có một số kernel đặc trưng giúp chúng ta có thể làm mờ hay làm sắc nét hình ảnh.

Ảnh 0‑14: ví dụ làm mờ ảnh

Ảnh 0‑15: Ví dụ làm sắc nét ảnh




















Bình luận