
itcctv_soft
19/07/2025
Giới thiệu về Deep Learning
.3.1. Giới thiệu về Deep Learning
Deep Learning (Học Sâu) là một lĩnh vực con của Machine Learning (Học Máy) và Trí tuệ Nhân tạo (AI), được phát triển với mục tiêu mô phỏng cách hoạt động của não bộ con người thông qua các mạng nơ-ron nhân tạo. Đây là một trong những công nghệ cốt lõi đằng sau sự bùng nổ của AI trong thập kỷ qua và đã đạt được nhiều thành tựu đáng kể trong các lĩnh vực như xử lý ngôn ngữ tự nhiên (NLP), thị giác máy tính (computer vision), và nhận dạng giọng nói.
Mạng Nơ-ron Nhân Tạo (Artificial Neural Networks - ANN): Deep Learning sử dụng các mạng nơ-ron nhân tạo, lấy cảm hứng từ cách hoạt động của các nơ-ron trong não người. Mỗi nơ-ron trong mạng thực hiện các phép toán đơn giản và kết hợp lại để thực hiện các nhiệm vụ phức tạp hơn.
Khác với Machine Learning truyền thống, nơi các thuật toán thường dựa vào đặc trưng được con người thiết kế thủ công, Deep Learning có khả năng tự động trích xuất đặc trưng từ dữ liệu thông qua quá trình huấn luyện.
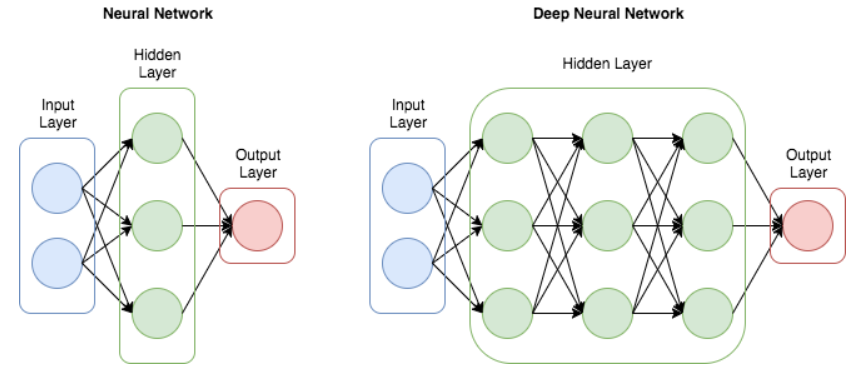
Deep Learning là mạng nơ-ron mà trong có rất nhiều tầng, mỗi tầng là 1 mạng nơ-ron nhỏ. Deep Learning đã đạt được những tiến bộ lớn trong nhận dạng hình ảnh, phân loại đối tượng, và các ứng dụng như xe tự hành, giám sát an ninh, và phân tích y tế. Các mô hình ngôn ngữ sâu như GPT, BERT đã cách mạng hóa cách chúng ta xử lý văn bản, dịch máy, và giao tiếp với chatbot. Deep Learning được sử dụng để cải thiện hiệu suất nhận dạng giọng nói trong các ứng dụng như trợ lý ảo, dịch vụ tổng đài tự động, và chuyển đổi giọng nói thành văn bản. Các hệ thống như gợi ý video trên YouTube, sản phẩm trên Amazon, hoặc nội dung trên Netflix đều dựa vào Deep Learning để đưa ra các khuyến nghị phù hợp với người dùng. Deep Learning đã được sử dụng để phát triển các AI có khả năng chơi các trò chơi phức tạp như cờ vua, cờ vây, và trò chơi điện tử.
Có một số thách thức mà Deep Learning đang đối mặt đó là: yêu cầu tài nguyên tính toán cao; vấn đề quá khớp (overfitting); thiếu hiểu biết trực quan (interpretability). Huấn luyện các mô hình Deep Learning, đặc biệt là những mô hình lớn, đòi hỏi lượng lớn tài nguyên tính toán và thời gian. Do tính phức tạp của mô hình, Deep Learning dễ mắc phải hiện tượng quá khớp, khi mô hình học thuộc lòng dữ liệu huấn luyện mà không thể tổng quát hóa tốt cho dữ liệu mới. Deep Learning thường bị xem là "hộp đen" do khó hiểu được cách mà mô hình đưa ra các quyết định, điều này đặt ra những thách thức về tính minh bạch và giải thích trong các ứng dụng quan trọng.
Deep Learning sẽ tiếp tục phát triển với các mô hình ngôn ngữ lớn hơn và mạnh mẽ hơn, có khả năng thực hiện nhiều nhiệm vụ khác nhau từ một mô hình duy nhất. Các phương pháp học không cần giám sát và học liên kết (federated learning) đang được phát triển để giảm thiểu yêu cầu về dữ liệu gắn nhãn và bảo vệ quyền riêng tư của người dùng. Có nhiều nỗ lực trong việc cải thiện tính minh bạch và công bằng của Deep Learning, nhằm đảm bảo rằng các mô hình AI có thể được tin tưởng và áp dụng một cách an toàn trong các lĩnh vực nhạy cảm.
4.3.2. Mạng nơ-ron nhân tạo
Mạng nơ-ron là sự kết hợp giữa trí tuệ nhân tạo và thiết kế lấy cảm hứng từ não bộ, định hình lại điện toán hiện đại. Với các lớp phức tạp của các nơ-ron nhân tạo được kết nối với nhau, các mạng này mô phỏng hoạt động phức tạp của não người, cho phép đạt được những kỳ tích đáng chú ý trong học máy. Có nhiều loại mạng nơ-ron khác nhau, từ truyền thẳng đến tuần hoàn và tích chập, mỗi loại được thiết kế riêng cho các nhiệm vụ cụ thể.
Mạng nơ-ron nhân tạo có một số lượng lớn các thành phần xử lý được kết nối với nhau, còn được gọi là các nút. Các nút này được kết nối với các nút khác bằng liên kết kết nối. Liên kết kết nối chứa các trọng số, các trọng số này chứa thông tin về tín hiệu đầu vào. Mỗi lần lặp lại và đầu vào lần lượt dẫn đến việc cập nhật các trọng số này. Sau khi nhập tất cả các trường hợp dữ liệu từ tập dữ liệu đào tạo, các trọng số cuối cùng của Mạng nơ-ron cùng với kiến trúc của nó được gọi là Mạng nơ-ron được đào tạo. Quá trình này được gọi là Đào tạo Mạng nơ-ron. Các mạng nơ-ron được đào tạo này giải quyết các vấn đề cụ thể như được định nghĩa trong câu lệnh vấn đề.
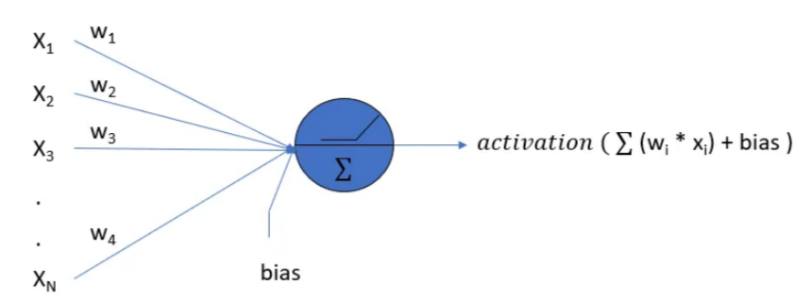
Ảnh 4‑6: Cấu trúc của một nơ ron
Học sâu (Deep Learning) là một lĩnh vực của học máy (Machine Learning) tập trung vào việc đào tạo các mạng nơ-ron nhân tạo có nhiều lớp, được gọi là mạng nơ-ron sâu, để học và trích xuất các biểu diễn có ý nghĩa từ lượng dữ liệu lớn.
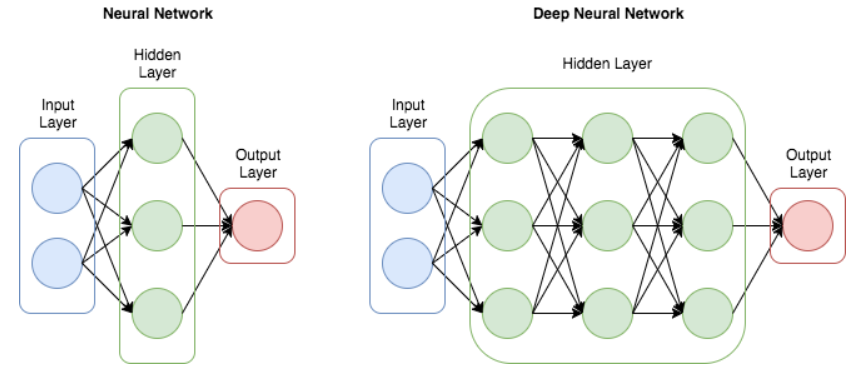
Ảnh 4‑7: Cấu trúc của một mạng nơ-ron đơn giản và mạng nơ-ron sâu
Một số khái niệm quan trọng trong mạng nơ-ron:
- Trọng số: quyết định mức độ quan trọng của từng đầu vào đối với nơ-ron. Trong quá trình huấn luyện, trọng số được điều chỉnh thông qua các thuật toán tối ưu hóa để giảm thiểu sai số của mô hình.
- Hàm Kích Hoạt (Activation Function): Hàm kích hoạt là một hàm toán học được áp dụng cho đầu ra của nơ-ron sau khi đã thực hiện tổng có trọng số. Các hàm kích hoạt phổ biến bao gồm: ReLU (Rectified Linear Unit): Trả về giá trị của đầu vào nếu lớn hơn 0, và trả về 0 nếu nhỏ hơn 0; Sigmoid: Biến đổi đầu vào thành một giá trị trong khoảng từ 0 đến 1; Tanh: Biến đổi đầu vào thành một giá trị trong khoảng từ -1 đến 1. Hàm kích hoạt sẽ làm mất đi tính tuyến tính của mạng nơ-ron.
- Hàm Mất Mát (Loss Function): Hàm mất mát đo lường sự khác biệt giữa dự đoán của mô hình và giá trị thực tế. Mục tiêu của quá trình huấn luyện là giảm thiểu giá trị của hàm mất mát này.
- Lan truyền ngược (Backpropagation): Lan truyền ngược là quá trình tính toán đạo hàm của hàm mất mát đối với từng trọng số trong mạng nơ-ron, sau đó cập nhật các trọng số này để giảm sai số. Thuật toán này dựa trên quy tắc chuỗi (chain rule) của đạo hàm, cho phép tính toán gradient của hàm mất mát một cách hiệu quả từ đầu ra trở về đầu vào, qua các tầng của mạng nơ-ron.
- Chuẩn hóa Theo Lô (Batch Normalization): là một kỹ thuật chuẩn hóa phổ biến trong các mạng nơ-ron sâu, được giới thiệu để giảm thiểu sự thay đổi về phân phối của các đầu ra của mỗi tầng trong quá trình huấn luyện. Điều này giúp tăng tốc độ huấn luyện và cải thiện hiệu suất, giảm thiểu vấn đề gradient vanishing hoặc exploding.
Mạng nơ-ron có thể được phân loại thành một số loại dựa trên cấu trúc của chúng: Mạng nơ-ron sâu (DNN), Mạng nơ-ron được kết nối đầy đủ (Multi-Layer Perceptron - MLP), Mạng nơ-ron tích chập (CNN), Mạng nơ-ron hồi quy (RNN). Một mạng nơ-ron có 2 hoặc nhiều lớp ẩn được gọi là DNN. Nếu tất cả các nơ-ron trong một lớp được kết nối với mọi nơ-ron trong lớp tiếp theo, tạo thành một cấu trúc được kết nối đầy đủ, thì mạng nơ-ron đó được gọi là Mạng nơ-ron kết nối đầy đủ.
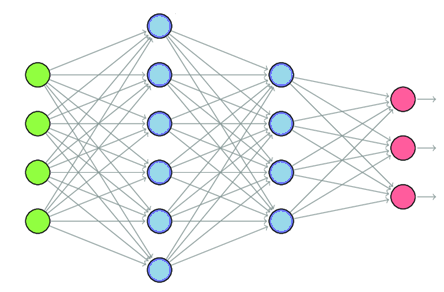
Ảnh 4‑8: Mạng nơ-ron kết nối đầy đủ
CNN (mạng nơ-ron tích chập) là một loại mạng nơ-ron sâu được thiết kế riêng để xử lý dữ liệu dạng lưới, chẳng hạn như dữ liệu hình ảnh. Nó được sử dụng rộng rãi để trích xuất thông tin, nhận dạng khuôn mặt, v.v., đặc biệt là để xử lý hình ảnh và video. Nó sử dụng các phép toán tích chập và học các đặc điểm của hình ảnh. Lớp cuối cùng làm phẳng các đặc điểm thành một tập hợp các lớp được kết nối đầy đủ (nói cách khác, một perceptron nhiều lớp) để thực hiện phân loại hoặc phát hiện đối tượng.
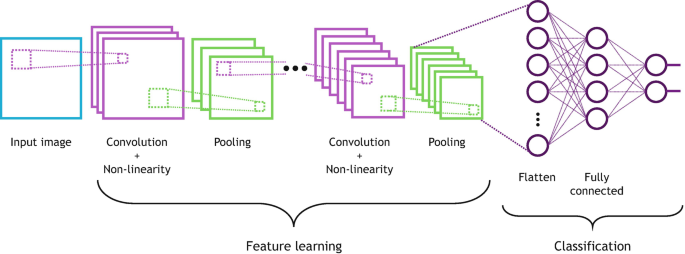
Ảnh 4‑9: Cấu trúc của một mạng nơ-ron tích chập (CNN) cơ bản
Mạng nơ-ron hồi quy (RNN) phù hợp với dữ liệu tuần tự, chẳng hạn như chuỗi thời gian hoặc dữ liệu ngôn ngữ tự nhiên, bằng cách cho phép kết nối giữa các nút để tạo thành các chu kỳ có hướng. RNN có thể nắm bắt các phụ thuộc về thời gian và ngữ cảnh. Nó chia sẻ các tham số qua nhiều bước do đó làm giảm các tham số đào tạo và giảm chi phí tính toán.
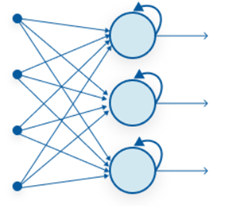
Ảnh 4‑10: Cấu trúc mạng RNN
Transformer là một kiến trúc mạng nơ-ron mới, đặc biệt hiệu quả trong xử lý ngôn ngữ tự nhiên. Nó sử dụng cơ chế attention để tìm kiếm các mối liên hệ giữa các phần của đầu vào, cho phép song song hóa tính toán và cải thiện hiệu suất so với RNN truyền thống.
Mạng tạo sinh (Generative Models) là một nhóm mô hình trong học sâu có khả năng học và tạo ra dữ liệu mới giống dữ liệu gốc. Chúng đặc biệt quan trọng trong các ứng dụng như tạo ảnh, video, văn bản, Deepfake (giả mạo khuôn mặt, giọng nói).
Thách thức và tương lai của mạng nơ-ron:
- Khả năng giải thích (Interpretability): Một trong những thách thức lớn nhất là làm thế nào để giải thích và hiểu được cách mà mạng nơ-ron đưa ra quyết định, đặc biệt trong các ứng dụng nhạy cảm như y tế và tài chính.
- Hiệu quả tính toán: Huấn luyện các mạng nơ-ron lớn đòi hỏi tài nguyên tính toán khổng lồ và tiêu thụ năng lượng lớn. Điều này thúc đẩy các nghiên cứu về việc tối ưu hóa mô hình và sử dụng tài nguyên hiệu quả hơn.
- Mạng nơ-ron lai: Tương lai có thể chứng kiến sự phát triển của các mạng nơ-ron lai, kết hợp giữa nhiều kiến trúc khác nhau (như CNN + RNN) để tận dụng ưu điểm của từng loại và giải quyết các vấn đề phức tạp hơn.
Mạng neural là trái tim của Deep Learning và đã mang lại nhiều đột phá trong các lĩnh vực khoa học máy tính và ứng dụng thực tiễn. Việc hiểu rõ cấu trúc và nguyên lý hoạt động của các mạng này sẽ giúp bạn nắm bắt được tiềm năng và thách thức của chúng trong tương lai.
4.3.3. Kỹ Thuật Huấn Luyện Deep Learning
Huấn luyện Deep Learning không chỉ đơn giản là xây dựng mô hình mà còn cần các kỹ thuật tối ưu hóa để đạt được hiệu suất tốt nhất. Dưới đây là các kỹ thuật quan trọng trong huấn luyện Deep Learning, giúp cải thiện tốc độ hội tụ, giảm overfitting, và nâng cao độ chính xác.
Bước 1: chuẩn hóa dữ liệu
Trước khi huấn luyện, dữ liệu cần được chuẩn hóa để giúp mô hình học hiệu quả hơn. Ta có thể chuẩn hóa dữ liệu theo các cách sau:
Chuẩn hóa Min-Max Scaling (Giới hạn dữ liệu về khoảng [0,1] hoặc [-1,1])
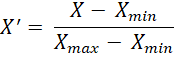
Hoặc Z-score Normalization (Chuẩn hóa theo phân phối chuẩn):
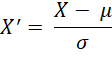
Hoặc Image Normalization (chuẩn hóa ảnh) là chia giá trị pixel cho 255 để đưa về khoảng [0,1].
Bước 2: Chọn hàm tối ưu (Optimization Algorithms)
Deep Learning sử dụng gradient descent để tối ưu trọng số, nhưng có nhiều biến thể giúp tăng tốc độ hội tụ.
Thuật toán | Đặc điểm | Ứng dụng |
SGD (Stochastic Gradient Descent) | Đơn giản, cập nhật từng batch nhỏ | Thường dùng trong CNN |
| Momentum | Giảm rung động, hội tụ nhanh hơn SGD | Tăng tốc cập nhật |
| RMSProp | Điều chỉnh tốc độ học theo lịch sử gradient | Dùng trong RNN |
| Adam (Adaptive Moment Estimation) | Kết hợp Momentum và RMSProp, rất phổ biến | Hầu hết các mô hình DL |
Bước 3: Điều Chỉnh Learning Rate (Learning Rate Scheduling)
Nếu learning rate quá cao sẽ làm mô hình dao động, không hội tụ, nếu quá thấp thì hội tụ chậm và mất nhiều thời gian. Giải pháp cho việc này đó là giảm learning rate sau một số epoch nhất định.
Bước 4: Regularization - Giảm Overfitting
Khi mô hình quá phức tạp, nó dễ overfit dữ liệu huấn luyện. Một số phương pháp giúp giải quyết vấn đề này:
- Dropout tắt ngẫu nhiên một số neuron trong quá trình huấn luyện, giúp giảm phụ thuộc vào một số đặc trưng nhất định.
- Chuẩn hóa đầu vào của mỗi layer giúp huấn luyện nhanh hơn.
- Tạo dữ liệu mới từ dữ liệu gốc để tăng độ đa dạng.
Bước 5: Tân dụng mô hình đã huấn luyên nếu có
Thay vì huấn luyện từ đầu, ta có thể tận dụng mô hình có sẵn và tinh chỉnh (fine-tuning) trên dữ liệu mới. Các mô hình như ResNet, VGG, BERT, GPT có thể được sử dụng lại.
Bước 6: Giám sát quá trình huấn luyên
Sử dụng TensorBoard để theo dõi loss, accuracy, learning rate. Sử dụng Early Stopping để dừng huấn luyện khi loss không cải thiện.
Bước 7: Huấn Luyện Mô Hình Trên GPU
Sử dụng GPU tăng tốc huấn luyện gấp 10-100 lần so với CPU. Một mô hình sẽ được huấn luyện nhiều lần trên bộ dữ liệu mỗi lần được gọi là 1 epoch. Thông thường số lần huấn luyện có thể đến 40 50 epoch tùy thuộc vào quy mô dữ liệu.

















Bình luận